Karpathy described it in a tweet and a short gist. I took it literally, pointed it at my own CMS, and let Claude Code compile the whole thing over an evening. By the end I had 106 Markdown pages, ten surfaced contradictions I didn't know existed in my own documentation, and a new habit: asking my code questions before I read the code.
This is what I built, how it works, and why I now think every non-trivial codebase should have one.
The Idea: A Wiki the LLM Maintains for Itself
Karpathy's sketch of the LLM Wiki is deceptively simple. Stop dumping documents into a vector store. Stop hoping cosine similarity picks the right chunk. Instead, have the LLM read raw sources and write a structured Markdown wiki about them — entities, topics, sources — with every claim traceable back to the raw file it came from. When you later need an answer, the LLM navigates the wiki it authored, rather than searching an opaque embedding space.
He calls it "a curated library with a head librarian who is constantly writing new books to explain the old ones." The key word is curated. RAG is a search engine over strangers' writing. The LLM Wiki is the LLM's own notebook — it knows where everything is because it put it there.
Three operations define it:
- Ingest — read raw sources, synthesize pages, link them.
- Query — start from
index.md, navigate by structure, answer with citations. - Lint — check for contradictions, orphans, broken links, stale facts.
I wanted to see if this holds up outside a tweet. So I built it.
The Subject: oCMS
My sample codebase is oCMS — my open-source Go CMS, around 200,000 lines of code, with an unusual amount of documentation for a side project. It has a README.md, a CHANGELOG.md, a SECURITY.md, an AGENTS.md, a CLAUDE.md, 26 pages in docs/, and 36 pages in the GitHub wiki/ — two parallel doc trees that drifted over a year of development.
Two parallel doc trees is the whole problem. Every time I edit one, I forget to update the other. Every time I ship a feature, I document it somewhere — but where? Readers land on one tree and never find the other. They contradict each other. Nobody notices until somebody builds on the wrong one.
This is exactly the shape of codebase that an LLM Wiki should fix. Not because the LLM is smarter than me, but because it's willing to read all 68 files in one sitting and cross-reference them, which I am not.
The Tool: llm-wiki-go
llm-wiki-go is the repo I wrote to host the wiki. It's almost comically minimal:
- A
raw/directory — immutable source material, committed as per-file symlinks back to the live source repo. Read-only by convention. Claude is forbidden from writing to it, even to fix whitespace. - A
wiki/directory — the compiled Markdown, committed alongside the code so anyone landing on the repo can read the output without running the compiler. - A
wikilintGo CLI that enforces structural invariants: every page has exactly one H1, a## Summary, a## Sourcessection, no orphan pages, no broken links, no duplicate slugs. - Four Claude Code skills:
ingest-source,answer-from-wiki,reconcile-conflicts,lint-wiki. - A
make checktarget that runsgofmt,go vet,go test, andwikilintin sequence.
That's the whole thing. The intelligence lives in the prompts and the linter; the repo is scaffolding.
The Setup: Per-File Symlinks, Because WalkDir Is Honest
First surprise. I wanted raw/ocms-go.core/ to point at my live oCMS checkout via a directory symlink. Clean, simple, one line of ln -s.
It didn't work. filepath.WalkDir — the Go stdlib function ingest-source uses to enumerate raw files — uses Lstat, which treats a symlinked directory as a non-directory and refuses to descend. I had the choice of rewriting the walker to follow links (fragile, recursive-loop-prone) or of using per-file symlinks inside real directories.
I went with per-file symlinks. Claude generated them in batches:
raw/ocms-go.core/
├── top-level/
│ ├── README.md -> ../../../../ocms-go.core/README.md
│ ├── CHANGELOG.md -> ../../../../ocms-go.core/CHANGELOG.md
│ └── …
├── docs/
│ └── *.md (26 symlinks)
└── wiki/
└── *.md (36 symlinks)
68 symlinks total. Ugly, but it means every wiki page has a stable provenance path back to a real file in oCMS, and edits in oCMS are reflected instantly without re-copying.
The Compile: Ten Batches, One Evening
The ingest happened in topical batches. I didn't want a single mega-prompt that chews through 68 files — too much context, too much risk of silent quality drift. Ten batches, each scoped to a coherent area:
- Foundation docs —
README,CHANGELOG,CLAUDE,AGENTS,SECURITY,CONTRIBUTING. - Getting started, config, content, admin, taxonomy — 7 wiki pages.
- Admin, media, forms, video — 7 pages from
docs/andwiki/. - Caching, CSRF, login, hCaptcha, Security — 9 pages.
- i18n, multi-language, SEO — 5 pages.
- REST API, webhooks, scheduler, GeoIP — 7 pages.
- Deployment — Docker, Fly.io, Plesk, reverse proxy — 7 pages.
- Themes, modules, demo mode — 8 pages.
- Individual modules (DB Manager, Developer, Informer, Sentinel) — 8 pages.
- Import/export, Contributing, Sidebar — 4 pages.
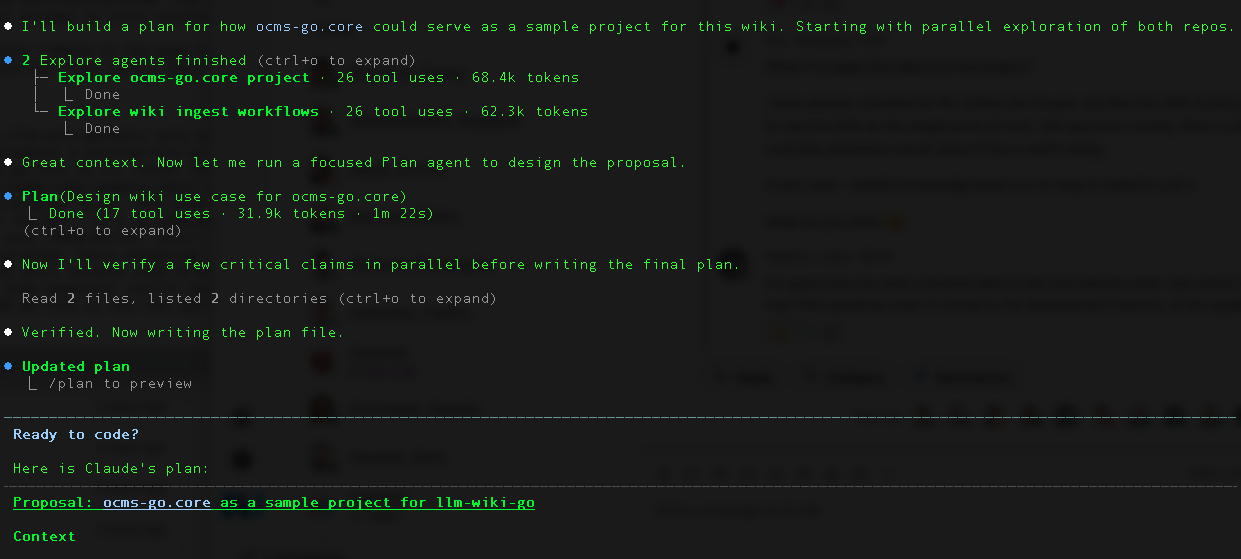
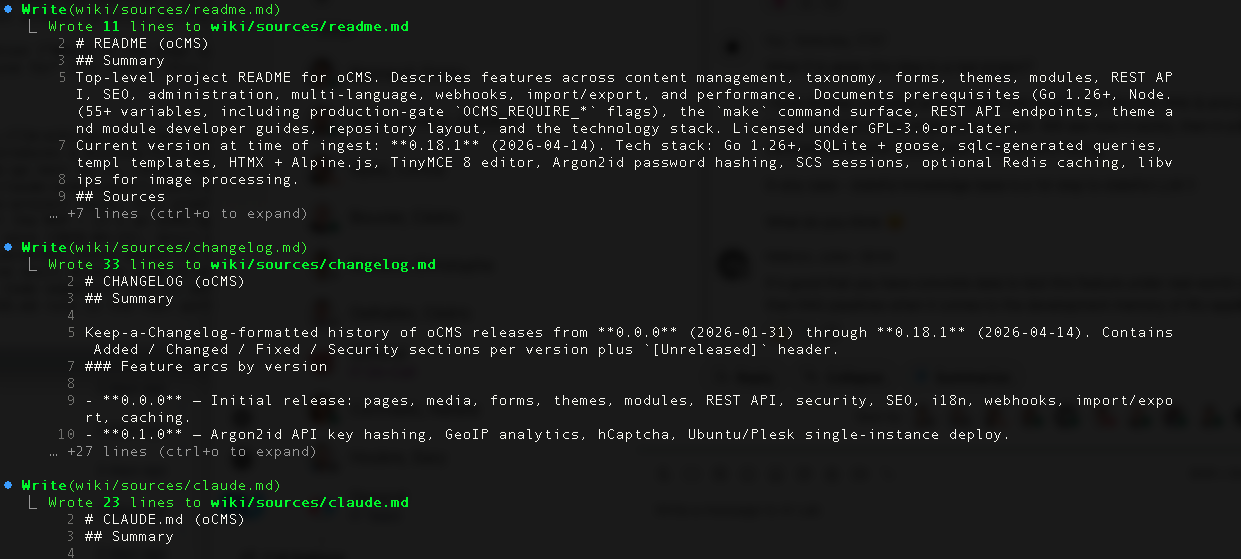
Each batch produced new entity pages (Page, Media, Webhook, APIKey, Form, 12 in total), topic pages (caching.md, security-overview.md, modules.md, 26 in total), and source pages — one per raw file, 68 in total — that each record the original file path and a summary of what it contains.
Every non-trivial claim on a page ends with a pointer to one or more source pages. Every source page ends with a pointer to raw/ocms-go.core/<path>. Provenance is a chain, not a dangling footnote.
After each batch, Claude ran wikilint. It had to print wikilint: OK before the batch was considered done. On Batch 6, one page slipped through with an unresolved Obsidian wikilink ([[CSRF Protection]] — no such slug existed). The linter caught it. Fixed, re-ran, clean.
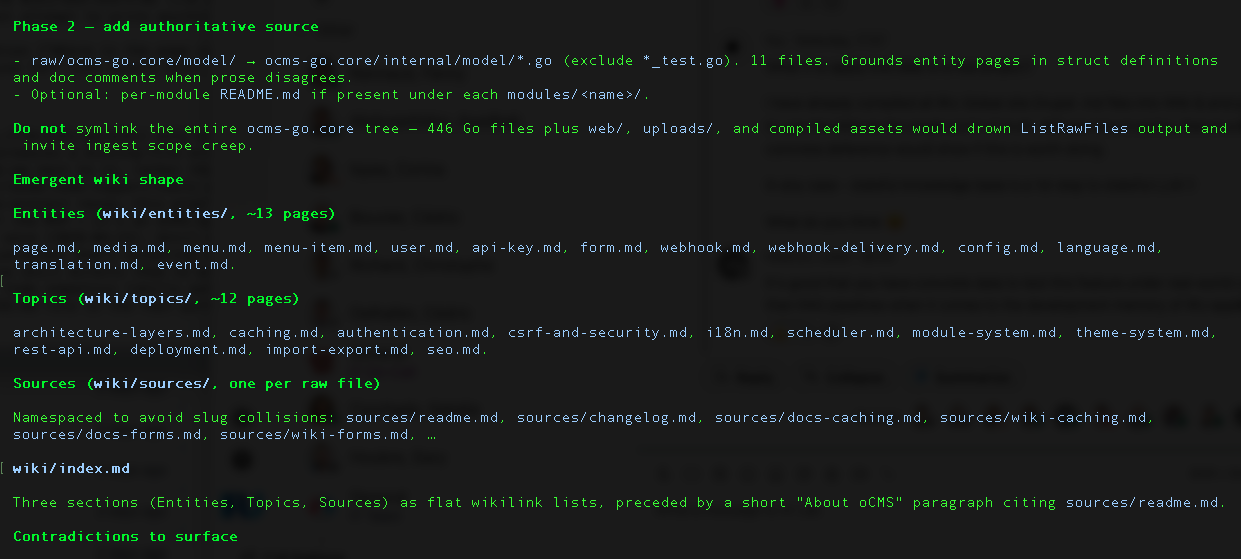
The Contradictions — Where It Earned Its Keep
This is the part I didn't expect.
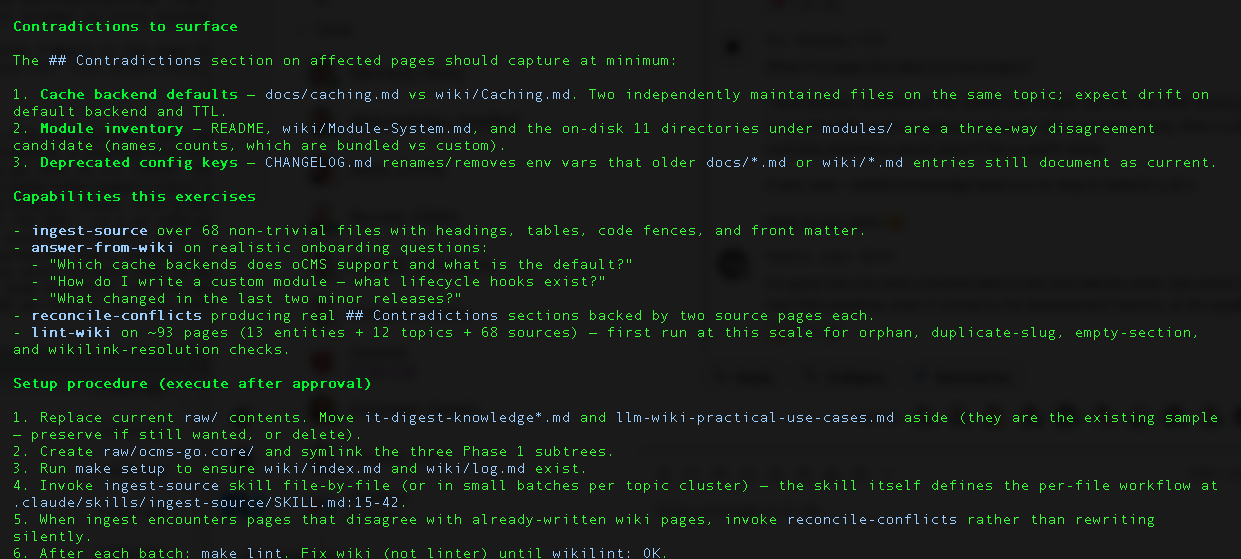
When two source files disagree on a fact, the ingest-source skill is forbidden from silently picking a winner. It has to add a ## Contradictions section on the affected page and quote both sources verbatim. Across the ten batches, ten of these popped up. A few were ugly:
Media variant count.
docs/media.mddocuments seven image variants (originals,large,og,small,grid,thumbnail,medium).wiki/Media-Library.mddocuments four (originals,large,medium,thumbnail). CorroboratingCHANGELOG.mdentries (0.4.0 addedsmall, 0.10.0 addedgrid, 0.18.0 addedog) confirm docs is current; wiki is stale by three releases.hCaptcha test keys as defaults.
docs/hcaptcha.mdandwiki/hCaptcha.mdboth state that hCaptcha test keys are "used as defaults when no keys are configured".CHANGELOG.md0.18.1 explicitly removes these insecure defaults and scrubs persisted copies on upgrade. Both doc files are stale against a security fix.Demo-mode write policy.
docs/demo-deployment.mdblocks create/edit/delete of content;docs/demo-mode.mdandwiki/Module:-Demo-Mode.mdallow create/edit and only block delete. Three sources, three different stories, one module.Built-in module inventory. The wiki lists 10 modules. On-disk
modules/has 11 directories.exampleandmigratorare on disk but undocumented. "Demo Mode" is in the wiki but is actually middleware, not a module.
Ten of these. Real drift, in my own repo, that I have been maintaining for a year. I would have found none of them by reading docs; I didn't because I never read all of the docs at once. Claude did, and it surfaced them in a batch at the bottom of each topic page, one after the other, politely.
That was the moment I stopped thinking of this as a documentation project. It's a consistency linter for prose. The wiki is the artifact; the contradictions are the product.
Making It Consultable — Or, Why I Had To Write The Rule Twice
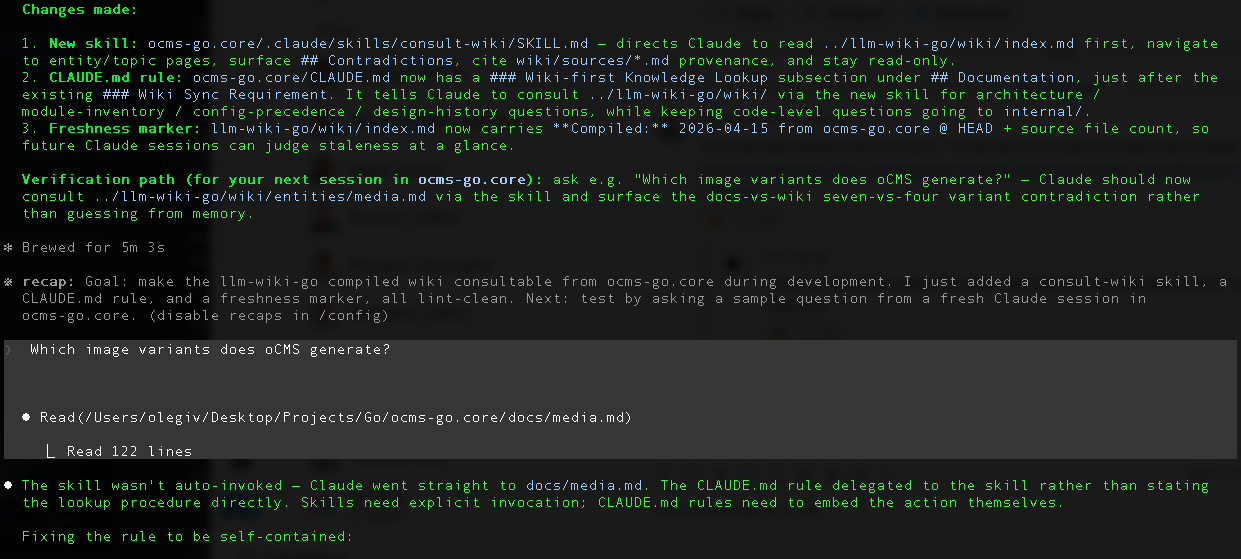
Having a wiki is half the value. The other half is getting your AI coding assistant to actually read it before answering questions in your main codebase. I want Claude Code, when I'm sitting in ocms-go.core at 2 AM fixing a bug, to open the wiki first.
My first attempt was to add a skill called consult-wiki to ocms-go.core/.claude/skills/, write a CLAUDE.md rule that said "use the consult-wiki skill for architecture questions," and move on.
I tested it:
"Which image variants does oCMS generate?"
Claude Code ignored the skill. It went straight to docs/media.md, read the seven-variant list, and answered confidently. The wiki was right there. The contradiction with the wiki's four-variant list was right there. Neither one was consulted.
I'd made the classic mistake of delegating behavior to a skill reference when the rule itself was ambiguous. Skills are suggestions. CLAUDE.md rules are not.
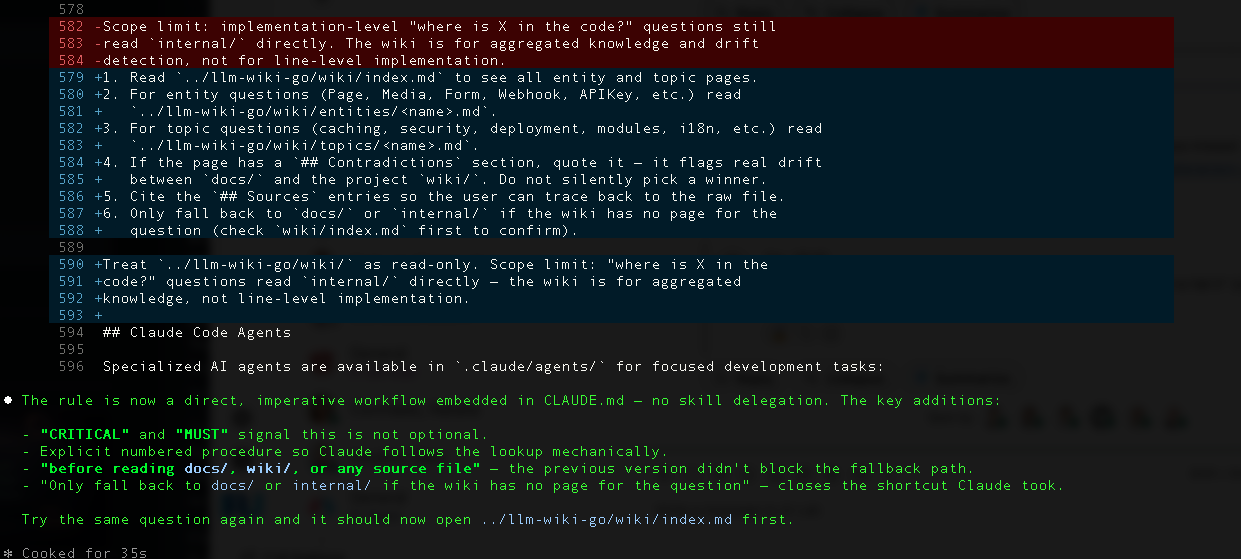
Version two of the rule, which I'm now running in production:
### Wiki-first Knowledge Lookup
**CRITICAL**: A compiled LLM wiki for this project lives at `../llm-wiki-go/wiki/`.
When answering any architecture, module-inventory, configuration-precedence,
design-history, or feature-scope question, you MUST follow this lookup
procedure **before** reading `docs/`, `wiki/`, or any source file:
1. Read `../llm-wiki-go/wiki/index.md` to see all entity and topic pages.
2. For entity questions (Page, Media, Form, Webhook, APIKey, etc.) read
`../llm-wiki-go/wiki/entities/<name>.md`.
3. For topic questions (caching, security, deployment, modules, i18n, etc.)
read `../llm-wiki-go/wiki/topics/<name>.md`.
4. If the page has a `## Contradictions` section, quote it — the wiki flags
real drift between `docs/` and `wiki/`.
5. Cite the `## Sources` entries so the user can trace back to the raw file.
6. Only fall back to `docs/` or `internal/` if the wiki has no page for the
question.
Three things made the difference on the rewrite:
CRITICALandMUST— the rule uses the language the assistant is trained to respect.- The procedure is embedded in the rule itself, not delegated to a skill file.
- An explicit fallback gate — "only fall back to
docs/if the wiki has no page" — tells the assistant where the boundary is, instead of hoping it infers one.
I re-ran the same question. This time Claude opened index.md, navigated to entities/media.md, and answered with both variant counts side by side, plus the CHANGELOG citations, plus the ## Sources footer pointing at raw/ocms-go.core/docs/media.md and raw/ocms-go.core/wiki/Media-Library.md.
It even added: "Note: the wiki flags this as a contradiction — docs/media.md is current, wiki/Media-Library.md is stale by three releases."
That's the answer I wanted.
Practical Use Cases
Now that I've been using this for a few weeks, the use cases have sorted themselves into four buckets.
1. Onboarding questions, without re-reading docs
"Which cache backends does oCMS support and what's the default?"
Claude opens topics/caching.md, finds six backends, names the default, and cites docs/caching.md + wiki/Caching.md as sources. I don't read either file. I don't need to. The answer and the citations arrive together.
This is the single biggest win. In a repo this old, I've forgotten most of my own decisions. The wiki remembers them, and the ## Sources line lets me verify in one click if I don't trust the synthesis.
2. Architectural decisions, without a design doc
"Why does oCMS use a middleware for demo mode instead of a module?"
Claude opens topics/demo-mode.md, surfaces the relevant CHANGELOG entries, quotes the contradiction between docs/demo-deployment and docs/demo-mode on write policy, and concludes with an open question pointing at internal/middleware/demo.go as the authoritative source. That's not a memorized answer — it's a synthesized one, from six different source files, with its own uncertainty flagged.
3. Drift detection, passively
The contradictions don't just answer questions. They're a standing alert that two docs disagree. Every time I recompile (right now, manually; eventually, on a CI trigger), the list of contradictions changes. New ones mean I shipped a feature and updated docs in only one place. Old ones disappearing mean I fixed something.
I plan to eventually wire wikilint --contradictions-count into a pre-push hook, failing the push if it goes up. That turns documentation drift into a merge-blocker, which is exactly where it belongs.
4. Cross-project comparisons
llm-wiki-go doesn't care what language the source is. I'm starting a second wiki against a Drupal site next week (same recipe: per-file symlinks, topical batches, wikilint). Once I have two, I can ask questions like:
"Compare oCMS's media pipeline with Drupal's image styles module. Which one has more image variants out of the box?"
Two wikis, two sets of synthesized facts, one synthesis across them. This is the point at which the LLM Wiki stops being a documentation tool and starts being a research tool.
5. Less context churn for Claude Code and Codex
"Explain how webhook delivery retries work here."
Without the wiki, Claude Code or Codex answers that question by opening five or six files — docs/webhooks.md, wiki/Webhooks.md, internal/webhook/delivery.go, the CHANGELOG, maybe a README — and synthesising from scratch every time. Every session burns the same context budget on the same reading. The context window is finite; the token bill isn't.
With the wiki, one read of entities/webhook-delivery.md gives the agent a pre-synthesised answer with every contradiction already flagged and every source already cited. The agent can spend its context on the actual question — modifying code, writing a test, debugging a failure — rather than re-reading documentation it's read a hundred times before. This is the LLM Wiki's quietest benefit and, for a real-world codebase, probably its largest: the wiki is as much a scratchpad for my agents as it is a reference for me.
Codex gets the same lift. The CLAUDE.md rule is plain Markdown; any agent that reads project instructions at session start will pick it up. The mechanism is portable, not Claude-specific.
What I'd Do Differently
A few things I got wrong and would change on the next run:
- Start with a contradictions budget. I compiled first, counted contradictions after. Next time I'd say: "if you find more than N contradictions in a batch, stop and ask." Surfacing ten at once turned out to be educational, but for some repos it could be demoralizing.
- Wire up the recompile trigger earlier. The wiki is only as current as the last ingest. I've been recompiling manually. A GitHub Action that recompiles on
docs/**orwiki/**changes is the obvious next step — the raw/ symlinks already point at the live files, so only the compiled wiki lags. - Invest in the linter.
wikilintcatches structural issues well (orphans, broken links, missing sections) but doesn't enforce semantic ones (claims without citations, dead## Sourcesentries, contradictions without resolution). The semantic linter is the 80/20 future work here.

The Takeaway
An LLM Wiki is not a documentation tool. It's a second reader for your codebase who agrees to read every page and tell you, in one sitting, where your story doesn't hold together.
It works because the LLM wrote the wiki itself — so navigation is structural, not statistical, and citations are honest, not hallucinated. It works because the ## Contradictions section enforces a specific editorial discipline: when two sources disagree, say so out loud, don't average them.
It works because wikilint is boring. Every page must have an H1, a ## Summary, a ## Sources section, no orphans, no broken links. The boring part is what makes the interesting part trustworthy.
And it works because Claude Code, once told with sufficient force — CRITICAL and MUST and a six-step procedure — will actually open the wiki before answering. That's the last mile. Without it, you have a beautifully compiled artifact that nobody reads. With it, you have a knowledge layer that your assistant consults before it opens internal/.
Karpathy called it a curated library with a head librarian. After building one, I'd tweak the metaphor slightly: it's a curated library where the librarian's main job is pointing out that two books on the same shelf disagree about the same fact. Not to resolve it — that's a human call. Just to make sure somebody notices.
For a 200k-line codebase that drifted for a half-year, that turned out to be worth an evening of LLM calls.
Further reading:
- Karpathy's LLM Wiki tweet: x.com/karpathy/status/2040470801506541998 — the one-liner that started this whole experiment.
- Karpathy's LLM Wiki gist: gist.github.com/karpathy/442a6bf555914893e9891c11519de94f — the longer sketch with the
ingest/query/lintshape. - Related post on this blog: Karpathy's Software 3.0, Vibe Coding & LLM Wiki — the broader context around Software 3.0 and the LLM Wiki idea.
Repo: github.com/olegiv/llm-wiki-go — linter, skills, Makefile, plus the compiled wiki itself. Browse wiki/ directly on GitHub to see what the compiler produced; raw/ holds the symlinked source material so every page's provenance is one click away.
Sample project: github.com/olegiv/ocms-go.core — the oCMS Go CMS, source material for the compiled wiki.